# (PART) Focus Topics {-}
# Overview
## Introduction
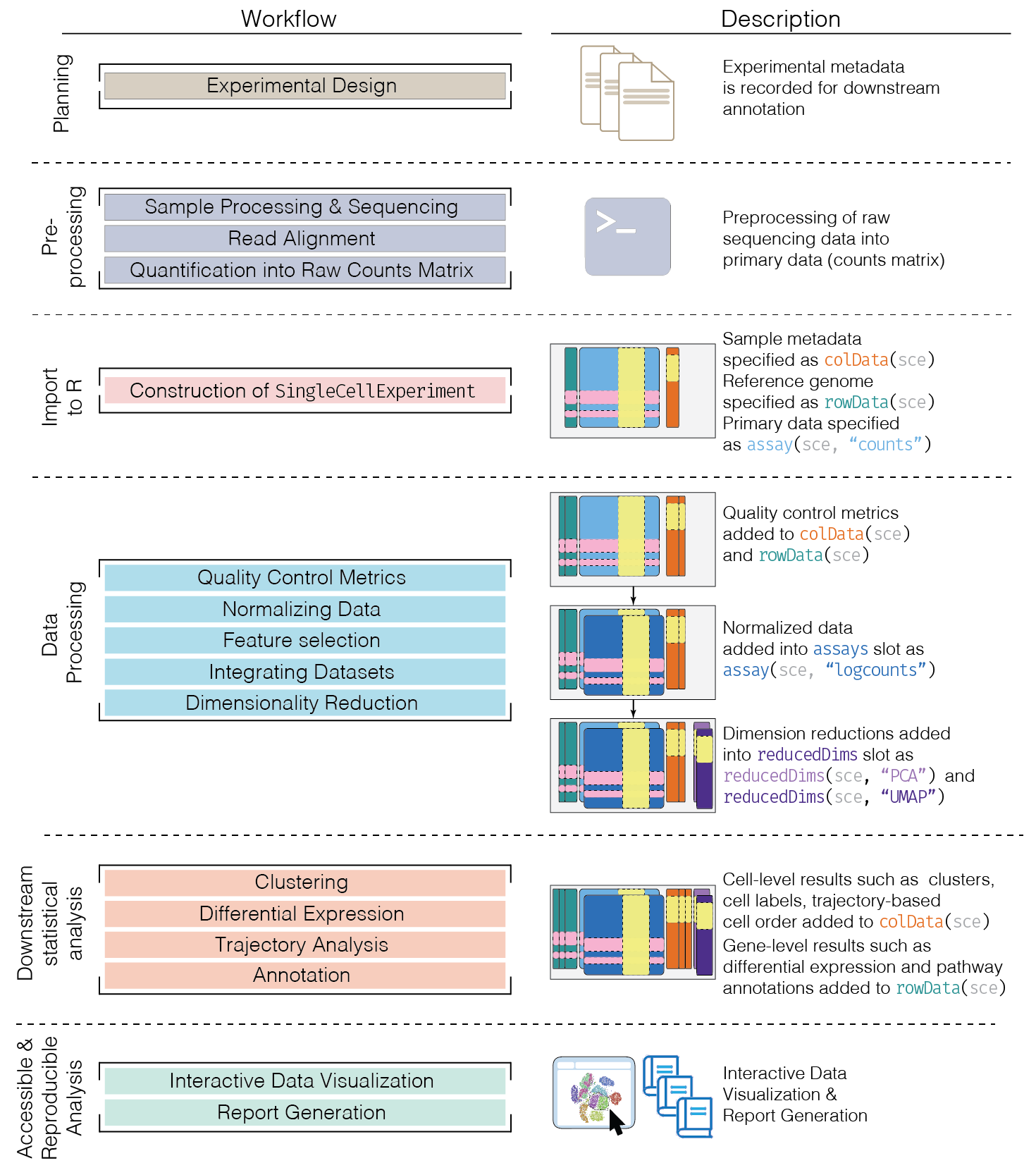
This chapter provides an overview of the framework of a typical scRNA-seq analysis workflow (Figure \@ref(fig:scworkflow)).
Subsequent chapters will describe each analysis step in more detail.
(\#fig:scworkflow)Schematic of a typical scRNA-seq analysis workflow. Each stage (separated by dashed lines) consists of a number of specific steps, many of which operate on and modify a `SingleCellExperiment` instance.
## Experimental Design
Before starting the analysis itself, some comments on experimental design may be helpful.
The most obvious question is the choice of technology, which can be roughly divided into:
- Droplet-based: 10X Genomics, inDrop, Drop-seq
- Plate-based with unique molecular identifiers (UMIs): CEL-seq, MARS-seq
- Plate-based with reads: Smart-seq2
- Other: sci-RNA-seq, Seq-Well
Each of these methods have their own advantages and weaknesses that are discussed extensively elsewhere [@mereu2019benchmarking;@ziegenhain2017comparative].
In practical terms, droplet-based technologies are the current _de facto_ standard due to their throughput and low cost per cell.
Plate-based methods can capture other phenotypic information (e.g., morphology) and are more amenable to customization.
Read-based methods provide whole-transcript coverage, which is useful in some applications (e.g., splicing, exome mutations); otherwise, UMI-based methods are more popular as they mitigate the effects of PCR amplification noise.
The choice of method is left to the reader's circumstances - we will simply note that most aspects of our analysis pipeline are technology-agnostic.
The next question is how many cells should be captured, and to what depth they should be sequenced.
The short answer is "as much as you can afford to spend".
The long answer is that it depends on the aim of the analysis.
If we are aiming to discover rare cell subpopulations, then we need more cells.
If we are aiming to characterize subtle differences, then we need more sequencing depth.
As of time of writing, an informal survey of the literature suggests that typical droplet-based experiments would capture anywhere from 10,000 to 100,000 cells, sequenced at anywhere from 1,000 to 10,000 UMIs per cell (usually in inverse proportion to the number of cells).
Droplet-based methods also have a trade-off between throughput and doublet rate that affects the true efficiency of sequencing.
For studies involving multiple samples or conditions, the design considerations are the same as those for bulk RNA-seq experiments.
There should be multiple biological replicates for each condition and conditions should not be confounded with batch.
Note that individual cells are not replicates; rather, we are referring to samples derived from replicate donors or cultures.
## Obtaining a count matrix
Sequencing data from scRNA-seq experiments must be converted into a matrix of expression values that can be used for statistical analysis.
Given the discrete nature of sequencing data, this is usually a count matrix containing the number of UMIs or reads mapped to each gene in each cell.
The exact procedure for quantifying expression tends to be technology-dependent:
* For 10X Genomics data, the `CellRanger` software suite provides a custom pipeline to obtain a count matrix.
This uses _STAR_ to align reads to the reference genome and then counts the number of unique UMIs mapped to each gene.
* Pseudo-alignment methods such as `alevin` can be used to obtain a count matrix from the same data with greater efficiency.
This avoids the need for explicit alignment, which reduces the compute time and memory usage.
* For other highly multiplexed protocols, the *[scPipe](https://bioconductor.org/packages/3.12/scPipe)* package provides a more general pipeline for processing scRNA-seq data.
This uses the *[Rsubread](https://bioconductor.org/packages/3.12/Rsubread)* aligner to align reads and then counts UMIs per gene.
* For CEL-seq or CEL-seq2 data, the *[scruff](https://bioconductor.org/packages/3.12/scruff)* package provides a dedicated pipeline for quantification.
* For read-based protocols, we can generally re-use the same pipelines for processing bulk RNA-seq data.
* For any data involving spike-in transcripts, the spike-in sequences should be included as part of the reference genome during alignment and quantification.
After quantification, we import the count matrix into R and create a `SingleCellExperiment` object.
This can be done with base methods (e.g., `read.table()`) followed by applying the `SingleCellExperiment()` constructor.
Alternatively, for specific file formats, we can use dedicated methods from the *[DropletUtils](https://bioconductor.org/packages/3.12/DropletUtils)* (for 10X data) or *[tximport](https://bioconductor.org/packages/3.12/tximport)*/*[tximeta](https://bioconductor.org/packages/3.12/tximeta)* packages (for pseudo-alignment methods).
Depending on the origin of the data, this requires some vigilance:
- Some feature-counting tools will report mapping statistics in the count matrix (e.g., the number of unaligned or unassigned reads).
While these values can be useful for quality control, they would be misleading if treated as gene expression values.
Thus, they should be removed (or at least moved to the `colData`) prior to further analyses.
- Be careful of using the `^ERCC` regular expression to detect spike-in rows in human data where the row names of the count matrix are gene symbols.
An ERCC gene family actually exists in human annotation, so this would result in incorrect identification of genes as spike-in transcripts.
This problem can be avoided by using count matrices with standard identifiers (e.g., Ensembl, Entrez).
## Data processing and downstream analysis
In the simplest case, the workflow has the following form:
1. We compute quality control metrics to remove low-quality cells that would interfere with downstream analyses.
These cells may have been damaged during processing or may not have been fully captured by the sequencing protocol.
Common metrics includes the total counts per cell, the proportion of spike-in or mitochondrial reads and the number of detected features.
2. We convert the counts into normalized expression values to eliminate cell-specific biases (e.g., in capture efficiency).
This allows us to perform explicit comparisons across cells in downstream steps like clustering.
We also apply a transformation, typically log, to adjust for the mean-variance relationship.
3. We perform feature selection to pick a subset of interesting features for downstream analysis.
This is done by modelling the variance across cells for each gene and retaining genes that are highly variable.
The aim is to reduce computational overhead and noise from uninteresting genes.
4. We apply dimensionality reduction to compact the data and further reduce noise.
Principal components analysis is typically used to obtain an initial low-rank representation for more computational work,
followed by more aggressive methods like $t$-stochastic neighbor embedding for visualization purposes.
5. We cluster cells into groups according to similarities in their (normalized) expression profiles.
This aims to obtain groupings that serve as empirical proxies for distinct biological states.
We typically interpret these groupings by identifying differentially expressed marker genes between clusters.
Additional steps such as data integration and cell annotation will be discussed in their respective chapters.
## Quick start
Here, we use the a droplet-based retina dataset from @macosko2015highly, provided in the *[scRNAseq](https://bioconductor.org/packages/3.12/scRNAseq)* package.
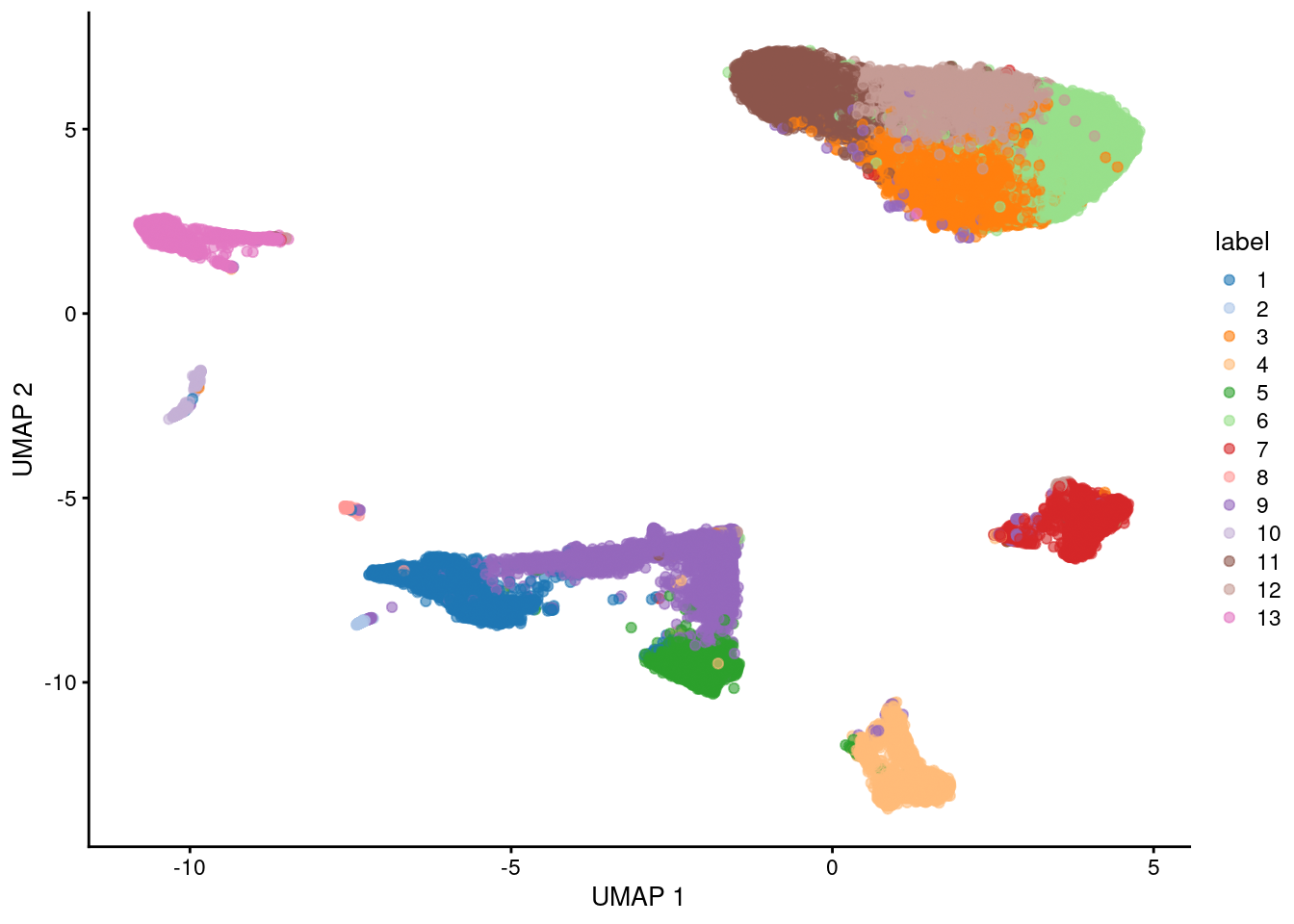
This starts from a count matrix and finishes with clusters (Figure \@ref(fig:quick-start-umap)) in preparation for biological interpretation.
Similar workflows are available in abbreviated form in the Workflows.,
```r
library(scRNAseq)
sce <- MacoskoRetinaData()
# Quality control.
library(scater)
is.mito <- grepl("^MT-", rownames(sce))
qcstats <- perCellQCMetrics(sce, subsets=list(Mito=is.mito))
filtered <- quickPerCellQC(qcstats, percent_subsets="subsets_Mito_percent")
sce <- sce[, !filtered$discard]
# Normalization.
sce <- logNormCounts(sce)
# Feature selection.
library(scran)
dec <- modelGeneVar(sce)
hvg <- getTopHVGs(dec, prop=0.1)
# Dimensionality reduction.
set.seed(1234)
sce <- runPCA(sce, ncomponents=25, subset_row=hvg)
sce <- runUMAP(sce, dimred = 'PCA', external_neighbors=TRUE)
# Clustering.
g <- buildSNNGraph(sce, use.dimred = 'PCA')
colLabels(sce) <- factor(igraph::cluster_louvain(g)$membership)
# Visualization.
plotUMAP(sce, colour_by="label")
```
(\#fig:quick-start-umap)UMAP plot of the retina dataset, where each point is a cell and is colored by the cluster identity.